Recently, I wondered whether songs were being increasingly released with entirely lowercase titles. I ended up using MusicBrainz’ library as a datasource, which comes packaged up as a Postgres database, but the data source I considered initially was one of Discogs’ monthly data dumps, which is made available for download as a set of (gzipped) XML files. The file I was interested in – the releases dataset – is 11.62 GB gzipped, 74 GB once decompressed. I wanted to iterate through every record and check for (a) entry quality, and (b) whether the track title was lowercase. Normally I’d use some kind of serialization framework, gesture at the shape of data, and then tell the framework to deserialize the whole object, but - that’s not an option when the file you’re working with is several times the RAM on your computer.
When you’re writing a deserializer and your file size is too big, the standard advice is to switch the deserializer into a “streaming” mode – the deserializer will tell you things like:
- here is a starting tag
- here is an ending tag
- here is a comment
… but this is significantly less ergonomic than being able to load the object into memory and then just access struct fields directly, especially once there’s several layers of nesting involved! One approach to handling a setup like this is to roll-your-own state machine, but I personally find complex state machines difficult to write and think about.
The data file in question has one top level <releases> tag, which contains something like 16 million <release> tags, each of which contains metadata, and a bundle of <tracks>.
Something like this:
<releases>
<release id="769" status="Accepted">
<images>...</images>
<artists>
<artist>
<id>194</id>
<name>Various</name>
<anv/>
<join/>
<role/>
<tracks/>
</artist>
</artists>
<title>Hi-Fidelity House Imprint One</title>
...
</release>
... 18 million times
</releases>
Each release is probably only a few kB in size (74 GB / 16 million releases); so the problematic part is the huge number of <release> entities. Maybe we can stream the <release>s, and then use a deserialization framework on the individual records that they’re more convenient to work with?
I ended up implementing a hybrid approach like this after googling around for a while and finding nothing. I’m documenting it here in the hope that it’s useful to you, dear Reader, for your esoteric large XML parsing tasks.
First attempt: try it in Python
Initially, I wrote this in Python. Python’s great for quick-and-dirty data parsing: I think it took around 20 minutes to write this code.
import argparse
import gzip
import bs4
from lxml import etree
def process_release(release):
# parse into something nice
soup = bs4.BeautifulSoup(
etree.tostring(release),
features='lxml-xml',
)
return todo_arbitrary_business_logic(soup)
def main():
# get filename from command line
argparser = argparse.ArgumentParser()
argparser.add_argument("--file")
args = argparser.parse_args()
filepath = args.file
# stream the compressed file so we don't have to unpack it
f = gzip.open(filepath)
# iterate through 'release' tags
context = etree.iterparse(f, tag=('release',))
for _action, element in context:
results = process_release(element)
todo_collate_results(results)
# release memory
element.clear()
if __name__ == "__main__":
main()
Unfortunately – Python’s also slow. I was watching the process in the activity monitor, and keeping an eye on how much data it had read from disk to get a sense for progress – and after around an hour it had processed around 10% of the file. I was 99% sure that the code wouldn’t be correct immediately, and didn’t want to have a ten hour iteration time, so something needed to change. Maybe I should unzip the file ahead of time, i.e. maybe the unzipping is the slow bit? That doesn’t sound right; the gzip code looks like it calls into native code1.
I guess I could parallelise the code? My computer’s got 8 cores, so maybe if I split the file into 8 pieces I could parse them all at the same time. The python script had been sitting at 100% CPU the whole time, meaning that the job was definitely CPU-bound and not I/O-bound, so parallelisation would probably help. But then I’d also have to figure out how to split a huge XML file into eight pieces, and there’s no good tools to do that easily, so I’d have to write a program… and I can probably get that correct in one go but then I’ve still gotta wait for a long time. Hmm.
Maybe let’s try rewriting in Rust?
A rewrite in Rust
It took a lot longer to write equivalent Rust code (~ 2 hours). I stumbled across quick-xml pretty quickly, and it works with serde, the classic Rust deserialization framework. But Rust is verbose and boilerplatey, and it can sometimes be hard to wrap your head around the abstractions that library authors choose.
After some googling, I found:
- someone had opened a GitHub issue asking exactly how to do this, even before
quick-xmlhadserdesupport. There’s mention in there about exactly my use case – switching from streaming to deserialization at a certain point – but the changes to make that possible don’t appear to have landed. - someone else had parsed a 38GB XML file with a full-blown state machine – there is a state diagram in there and it is making my head spin.
What I wanted to do was:
- Stream events to collect all the bytes that make up a
release - Parse that using serde to get a nice convenient datastructure.
Here’s the solution I landed on:
fn main() -> std::io::Result<()> {
// open file
let args: Vec<String> = env::args().collect();
let file_path = &args[1];
let file = File::open(file_path)?;
let gz = BufReader::new(GzDecoder::new(BufReader::new(&file)));
let mut reader = Reader::from_reader(gz);
let mut buf = Vec::new();
let mut junk_buf: Vec<u8> = Vec::new();
let mut count = 0;
let mut stats = HashMap::new();
// streaming code
loop {
match reader.read_event_into(&mut buf) {
Err(e) => panic!(
"Error at position {}: {:?}",
reader.buffer_position(),
e
),
Ok(Event::Eof) => break,
Ok(Event::Start(e)) => {
match e.name().as_ref() {
b"release" => {
// load entire tag into buffer
let release_bytes = read_to_end_into_buffer(
&mut reader,
&e,
&mut junk_buf
).unwrap();
let str = std::str::from_utf8(&release_bytes)
.unwrap();
// deserialize from buffer
let mut deserializer = Deserializer::from_str(str);
let release = Release::deserialize(&mut deserializer)
.unwrap();
// "business" "logic"
todo_process_release(&release, &mut stats);
count += 1;
if count % 1_000_000 == 0 {
println!("checked {} records", count);
}
}
_ => (),
}
}
// Other Events are not important for us
_ => (),
}
// clear buffer to prevent memory leak
buf.clear();
}
todo_print_results(&stats);
Result::Ok(())
}
The real trick is in that read_to_end_into_buffer method, which I copy-pasted from the quick-xml read_to_end method and modified. It’s basically a passthrough: it keeps reading elements til it hits the corresponding end tag, writes them all out to a buffer, and then returns the buffer. It’s worth noting that this isn’t efficient: we’re copying bytes out of the file into memory, and then presumably copying them around again into the data struct - but it’s maybe fast enough?
// reads from a start tag all the way to the corresponding end tag,
// returns the bytes of the whole tag
fn read_to_end_into_buffer<R: BufRead>(
reader: &mut Reader<R>,
start_tag: &BytesStart,
junk_buf: &mut Vec<u8>,
) -> Result<Vec<u8>, quick_xml::Error> {
let mut depth = 0;
let mut output_buf: Vec<u8> = Vec::new();
let mut w = Writer::new(&mut output_buf);
let tag_name = start_tag.name();
w.write_event(Event::Start(start_tag.clone()))?;
loop {
junk_buf.clear();
let event = reader.read_event_into(junk_buf)?;
w.write_event(&event)?;
match event {
Event::Start(e) if e.name() == tag_name => depth += 1,
Event::End(e) if e.name() == tag_name => {
if depth == 0 {
return Ok(output_buf);
}
depth -= 1;
}
Event::Eof => {
panic!("oh no")
}
_ => {}
}
}
}
Ok so: as you can see, a lot more fiddling, and a lot more code. How fast does it go?
time cargo run --release ~/Downloads/discogs_20230101_releases.xml.gz
Finished release [optimized] target(s) in 0.01s
Running `target/release/main /Users/fabian/Downloads/discogs_202
30101_releases.xml.gz`
checked 1000000 records
checked 2000000 records
...
cargo run --release ~/Downloads/discogs_20230101_releases.xml.gz
659.70s user 10.99s system 99% cpu 11:12.32 total
Wowweeee that’s so much better! We’re still clearly CPU bound:
If my computer had fans you would definitely be able to hear them right about now
… but eleven minutes instead of 10 hours is still a 55x performance boost. Not bad!
Are we actually CPU bound though?
I was talking someone through query optimisation in Postgres the other day and stumbled across a spooky line in the Postgres wiki:
Is CPU really the bottleneck? People often complain of pegged (100%) CPU and assume that’s the cause of database slowdowns. That’s not necessarily the case – a system may show an apparent 100% CPU use, but in fact be mainly limited by I/O bandwidth.
I wondered how this applied to the workload I had for this task – is there a chance we’re I/O-bound instead of CPU-bound? I mentioned earlier that the file I’m processing is 11.62 GB (gzipped), and the Macbook Air I was running this on can apparently read almost 3 GB / s (so fast!), so… probably not. We’d be I/O bound if we were processing this file in 4 seconds, not 10 minutes.
But! I’m still curious as to what the bottleneck is. Maybe it’s the file unzipping? Maybe it’s all the extra copying that we do when we read the data into a buffer? Lots of Rust libraries talk about being zero-copy, and so I’d always assumed that copies are slow.
We can find out empirically using cargo flamegraph, a ludicrously easy to use sampling profiler tool. The idea here is that the profiler periodically checks to see what code is executing right now and if you add that up over a long enough period of time, you’ve got a pretty good sense of what the slow part of your program is2.
I hypothesised that we’re experiencing slowness because of the two-pass construction that I’ve built, the bulk of which is in read_to_end_into_buffer. So let’s make sure that read_to_end_into_buffer is always visible to the sampling profiler by ensuring it’s never inlined:
#[inline(never)]
fn read_to_end_into_buffer<R: BufRead>(
// ...
And then we just follow the instructions in the cargo-flamegraph readme, and run:
# turn on debug symbols in release
export CARGO_PROFILE_RELEASE_DEBUG=true
# --root is because the profiler used by cargo flamegraph (dtrace)
# requires root
cargo flamegraph --root -- [args]
This produces a JS-powered interactive flamegraph – you can click around in it to zoom and focus on certain sections, and even search! You can interact with the full SVG file, but here’s a screenshot:
{kind=link}
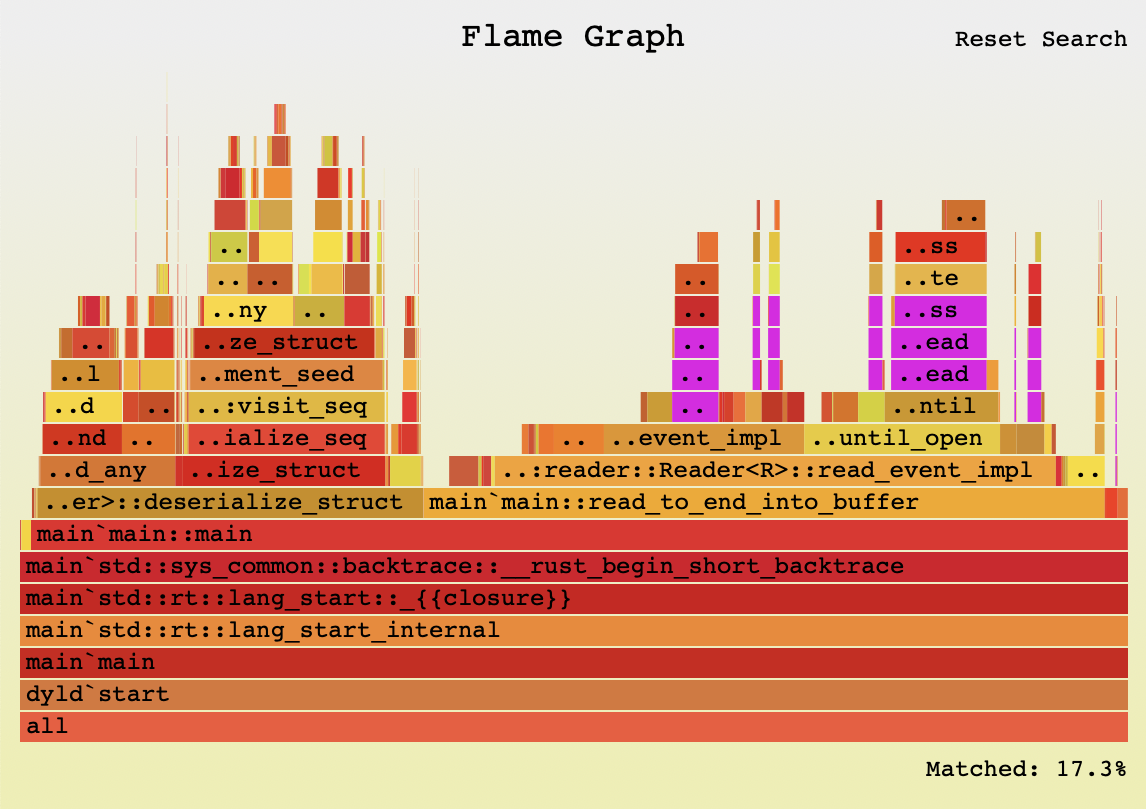
The purple bars match my search for ‘flate’, which is the crate that does the unzipping.
Some interesting things I noticed from clicking around and searching:
- unzipping the file on the fly accounts for about 17.3% of total time spent.
- 61% of the program time is the
read_to_end_into_buffermethod. That’s comprised of:- XML parsing: 55%
- The aforementioned unzipping: 17.3% of total time == about 28% of this method
- Copying bytes to the temp buffer: about 5%
- Other stuff: about 12%, including various moves / copies.
- 35% of the program time is deserialising into structs.
What’s particularly interesting to me about this is: the time deserializing into structs (35%) is roughly the same as the time spent parsing the XML so that we can put it into the temporary buffer (61% × 55% = 33%)!
So it seems like the slowest thing here is the XML parsing, and the problem with this approach with the temporary buffer is that you have to do it twice. If we were able to use Serde deserialization directly after we’d identified the start tag, we’d probably be able to get the total execution time down by something like 35%.
As I wrote the first iteration of this Rust code, I found myself thinking that it’d be great if the quick-xml library had a method to read the entire tag content into a buffer. The discussion on that issue I mentioned earlier suggests that a better solution would be a method which constructs a deserializer from a StartEvent and the input stream3, and now that I’ve seen that the slow bit in my implementation is just that we’re looking at every byte twice, I think that suggestion is probably right.
Rust is pretty good for tasks like this!
Rust has a real steep learning curve in general, and it definitely takes longer to write than python, even when you’re experienced. But it’s a pretty good candidate for tasks like this once you’ve got the hang of it!
If you’re also trying to parse extremely large XML files (whyyyyyy???), feel free to lift my code from Github, and if you figure out how to do the tricky solution without the string copies, let me know!
I didn’t test this assumption at the time, but upon googling there are a bunch of people complaining about gzip being slower in python than on the command line. ↩︎
On average / assuming the program behaves relatively consistently! Dan Luu unpacks this in a detailed post about a tracing system in use at Google. ↩︎
I’ve also spent the last 30 minutes wondering if the solution was right in front of my eyes the whole time; the people on that thread got so close to solving my exact problem that it’s uncanny 😅 ↩︎