Yesterday I released the first version of Grouse, a diff tool for websites generated with Hugo. There’s install instructions on Github and you can see the announcement post on the Hugo discussion forums. In this post, I’m going to discuss why I built Grouse, some of the design decisions I made, and some of the things I learned along the way.

The Black Grouse, Lyrurus Tetrix (von Wright brothers, 1828)
The brittleness of static site generators
This website has gone through a lot of revisions, but since 2013, it’s been a bunch of static HTML pages saved somewhere on the internet. About a month ago, I switched the process that produces those HTML files from Jekyll to Hugo because:
- I became frustrated with the process involved in keeping Jekyll and its requisite plugins running correctly
- It was pretty slow to build, which made iterating on a blog post pretty slow
- Hugo is new and shiny and switching allowed me to still feel productive while procrastinating on, y’know, actually writing something.
Rebuilding the site to work with Hugo was really fun, and Hugo is a really good tool, but like anything sufficiently complicated, it suffers from the problem where you think you’re making a single isolated change, and then something else on the site fundamentally changes too.
I’ve run into idiosyncrasies like this a couple of times whilst I’ve been operating capnfabs.net as a static site. Two concrete examples:
I recently broke the 🦖 404 page 🦖 when I was adding code which deletes unused high-resolution images from the site output
When I moved from Sydney to Berlin and then redeployed my site, all of the URLs changed because of a quirk in the way that Jekyll handles timezones 😬
At some point I decided I didn’t want to take any chances anymore, and that I’d carefully check over the generated site over before deploying it to the internet. But, it’s extremely tedious to check over every page, and there’s a bunch of stuff that I wouldn’t even think to check (like that 404 page).
However! In software development we have lots of great tools for verifying whether something has changed or not. The standard way of doing this is to compute a diff of the project. So, what if we could just diff the generated HTML before deploying it all to the internet?
A bash script to scratch the itch
I wrote the following bash script as a quick way of checking to see what has changed.
I’ve simplified it a little for brevity, and annotated it with comments to explain what it’s doing.
#!/usr/bin/env bash
# Turn two git revisions into concrete hashes.
# e.g. HEAD --> '72e76e93166f23b4f5f714dc62732dff3353ca74'
before=$(git rev-parse --verify "$1")
after=$(git rev-parse --verify "$2")
echo "Showing differences in output from $1 ($before) to $2 ($after)"
# Make temporary directories for storing working files
before_src=$(mktemp -d)
after_src=$(mktemp -d)
# Check out copies of the source at the given commits to the given
# temporary directories. See https://git-scm.com/docs/git-worktree
git worktree add --detach "$before_src" "$before"
git worktree add --detach "$after_src" "$after"
# Build the site at both the before and after commits, output gets
# saved to './public'
(
echo "Building first revision ($before)"
cd "$before_src";
hugo;
)
(
echo "Building second revision ($after)"
cd "$after_src";
hugo;
)
# Run a diff tool against the two generated outputs.
ksdiff "$before_src/public/" "$after_src/public/"Now, before deploying to the internet, I could run diff.sh HEAD^ HEAD to check for changes in the output before and after the newly-committed change. Prima!
Productionising the bash script
After using this consistently for a few weeks, and upon finding that it gave me a lot more confidence in deploying, I wondered if it would be useful to a broader audience, and decided to productionise it into something you could just download and run.
Taking a project from “sufficiently good to scratch your own itch” to “something useful to other humans” always takes much longer than you expect. In software development, we talk sometimes about an 80-20 rule – you can build something with 80% of the value for 20% of the effort, with the implication that getting that last 20% built takes 4 times as long as the first 80%. In my experience, it’s more extreme than this. You can whip up a bash script to solve a problem in 2 hours, but it’ll take two weeks to build something that solves the problem more generally and with a reasonable user experience1.
Bash is a terrifying and confusing language, so I decided to productionise this script in Go instead. Why Go?
Hugo is written in Go, and I thought it could be valuable to write the tool in the same language that the community was already working in for its main rallying project.
Having statically linked binaries is awesome for deployment. Something I’ve learned both from writing Python for work and from trying to maintain a Jekyll site (which is written in Ruby) is that having to install interpreters and dependencies, and ensure it all works, is a huge pain2. Being able to tell people “download and unzip this file and run it” is wonderful. It’s like the good ol’ days of Windows EXEs, without the bad-ol’ days of Visual C++ Redistributables (remember that?).
How does it work?
The core idea is the same as in that bash script! Breaking it down:
Step 1: Checkout the source at a specific commit to a temporary directory somewhere
We’re using a temporary directory instead of checking out / building in the current working directory because files that are ignored by source control can still be important for the build. A specific lesson that led to this decision was – my site was building fine locally, but on Netlify (my production webhost), the builds were timing out. The reason for the difference was:
- Hugo’s image processing step is pretty slow, so it caches processed images in
resources/_gen - This directory wasn’t checked in to source control on my machine
- When building locally, it was fast because the cached processed images were used, but when building on Netlify, these images had to be processed again.
Checking out to a temporary directory surfaces such problems ahead of deploy-time. It appears many other people are deploying using remote build services as well – Gitlab CI, Netlify and Github Actions, for example – so it seemed like a good thing to include.
Checking out the source turned out to be most of the complexity of the resultant code – rather than directly running git add-worktree as in the bash script, Grouse uses the go-git package to read the git repo directly, and then writes these files out to disk. I’m still really unsure as to whether this was a good idea or not – it seemed simple at the time, and then got more complicated as development continued 🙃.
go-git has functionality to clone a repo directly, but most git repos don’t support cloning specific commits, and I didn’t want to clone the whole repo (bad for performance) or go modifying the settings on the repo automatically (bad for UX) to make this work.
In addition to checking out the repo contents, there’s logic to automatically resolve and checkout specific commits for git submodules – Grouse will first try to resolve commits for submodules from the main working tree for the repo, but if the submodule isn’t in the working tree anymore, Grouse will clone the submodule into memory and extract the commit from there. Practically, this means that Grouse will still work correctly even if you’ve changed Hugo themes and deleted the old theme from your disk.
The submodule functionality is a prime example of extra work to support the generalised case. I don’t like git submodules – I find them scary and confusing – and so I avoid them, which meant I didn’t have to deal with them in my bash script. But if we want to make this useful for everyone, then we’re sorta stuck with supporting submodules, because the vast majority of Hugo documentation / blogs / community resources tell people to use them for theme installation:
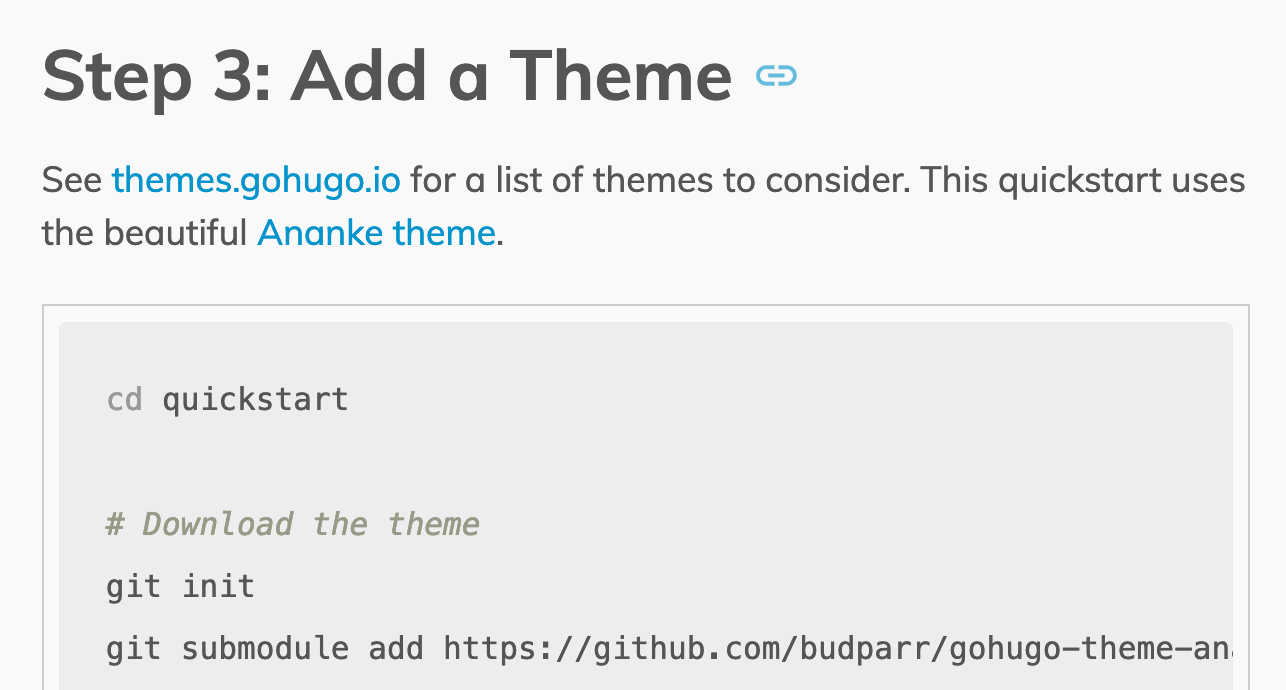
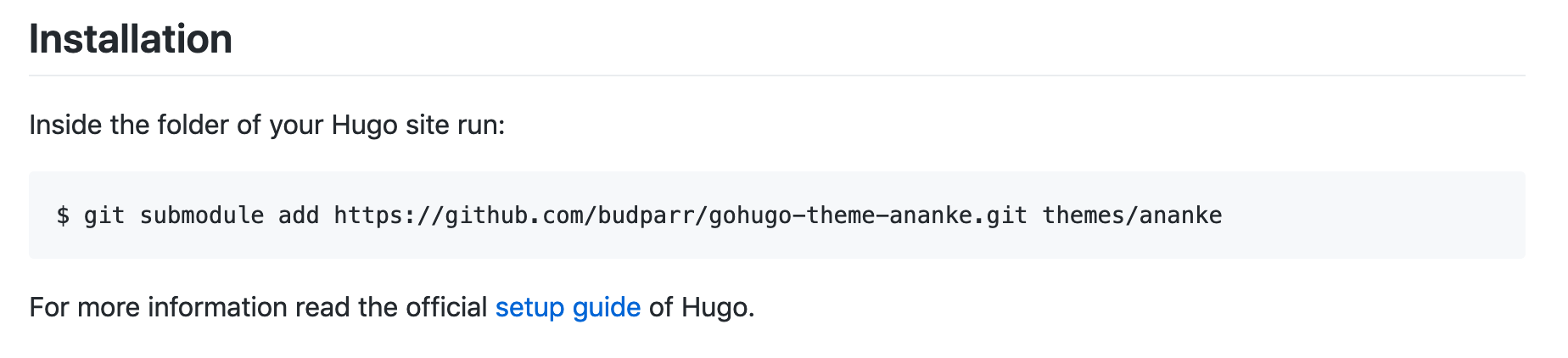
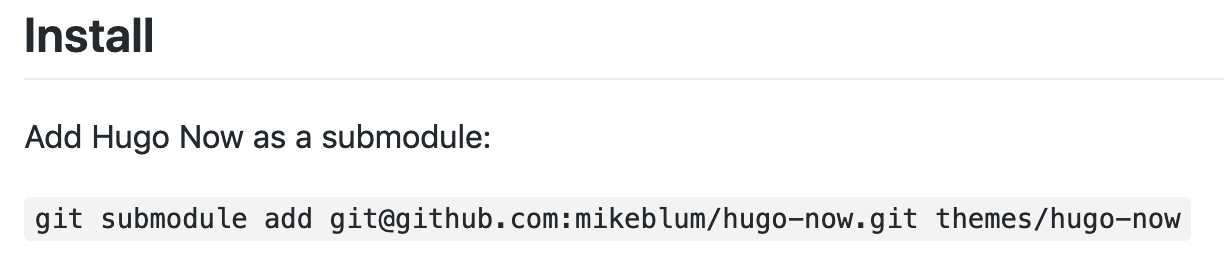
Step 2: Run Hugo Builds
This is about as straightforward as it was before. I’ll eventually want to support other static site generators as well, and then attempt to detect the generator in use, but for the time being, the grouse command just invokes hugo directly, as before.
Step 3: Run the diff
This has changed considerably as a result of productionising the tool. Previously, I was just running ksdiff, the Kaleidoscope diff tool, directly on the two output folders. I love Kaleidoscope, but it’s unreasonable to assume that everyone has it installed, because (a) it’s only available on OSX, and (b) it costs about USD 70 (I swear it was cheaper when I bought it).
The most sensible approach for this seemed to be just using whatever people’s standard git diff tool is – after all, the entire tool assumes that people are using git, so it’s probably a pretty safe bet that they’re comfortable-ish with git diff, and might even have a git difftool set up.
My first attempt at this was just to run git difftool --no-index, but --no-index apparently doesn’t support tools, and the result is that it just runs git diff. In the end, it seemed simpler to just reconstruct a git repo for the output so that git diff would be essentially working in the context it was designed for.
So the final process is:
- Init a git repo in a temporary directory
- Copy output for the “before” commit to that directory, and commit it
- Erase the contents of the directory
- Copy output for the “after” commit to that directory, and commit it
- Run
git diff HEAD^ HEADin this directory.
Diff args
Grouse supports passing arguments through to the diff step. I rarely use the bare form of git diff, and often use either git diff --stat or a graphical tool instead. So:
grouse --diffargs='--gui'will rungit diff --guigrouse --diffargs='--stat'will rungit diff --statgrouse --toolwill rungit difftool.
I’m not super happy with having --diffargs as a command-line option – I would’ve much preferred to have just passed through all args directly. For example:
grouse --guiwould rungit diff --guigrouse --statwould rungit diff --stat
This turns out to be impossible with Go’s flag package, and rolling my own flag parsing from scratch felt like overkill for a project like this, but I think it would afford a much nicer UX. A passthrough system allows you to say to users “just replace git diff with grouse and you’ll get a diff of your outputs”. It’s ludicrously easy to explain that, which is a good hint that it’s a much nicer UX. Maybe this will make it to a future version.
Shipping the v0.1
A question I asked myself again and again on this project – when do you ship the v0.1? Do you first ensure the user experience is perfect? Does it have to work perfectly for every repo from the get-go? Do you wait until after you’ve written the blog post explaining all your design decisions, to allay the fear that people will call you stupid for re-implementing a bunch of logic that’s probably already in the git command, or for writing an implementation that isn’t particularly efficient?
For me, it’s really easy to let your ego get caught up in the software you write, and, even after 7 years of doing this professionally, I still worry about looking like a fool. This happens less at work because we’ve got a strong culture of trust and mutual respect, but it’s still something I worry about when publishing stuff into the public sphere of the internet. The community around Hugo are pretty wholesome and helpful, however, and I’m looking forward to a day when that’s my default assumption of the response of strangers on the internet. We’ll get there at some point.
In then end, I decided a good way to get feedback while giving myself time and space to iron out the bugs gradually was to start with posting to the Hugo forums, and then as time and energy permits, expand Grouse laterally to support other static site generators. It’s definitely not the perfect tool yet! But the perfect is the enemy of the good, and if writing code really is just an outlet for expressing ideas, then I’m happy to have published an idea into the public sphere with this tool.
If you’re still here, thanks for reading! Again, go checkout Grouse on Github, and feel free to get in touch with any feedback.
This really caught me by surprising when I was building Timecard for Windows Phone, which was the first major piece of software I ever released – I hacked together a prototype in 5 hours on a rainy summer evening in Canberra. The version that eventually got pushed to the Windows Phone store took another 2 weeks of full-time work. ↩︎
The number of times I had to re-install the
rmagickRuby gem because Homebrew had randomly decided to upgrade my ImageMagick installation was too damn high. ↩︎